
The next AI era leaves the screen
Generative AI learned from the internet. Agentic AI is learning from digital tool use: code, browsers, terminals, calendars, email, and software environments where success can be checked. The next frontier is physical AI, where models must understand and control tools in the real world.
That shift changes the data problem. The internet gave language and image models an enormous training substrate. Software agents can generate and verify more data by using digital tools. Robots do not have that luxury yet. There are not enough humanoids, warehouse arms, field robots, surgical systems, or autonomous machines moving through the world and recording the observation-action traces needed to train general physical agents.
This is the chicken-and-egg problem at the center of robotics. Without enough deployed robots, there is not enough real robot data. Without enough robot data, the models stay too brittle. Because they are brittle, deployment stays limited.
Physical AI needs a data flywheel
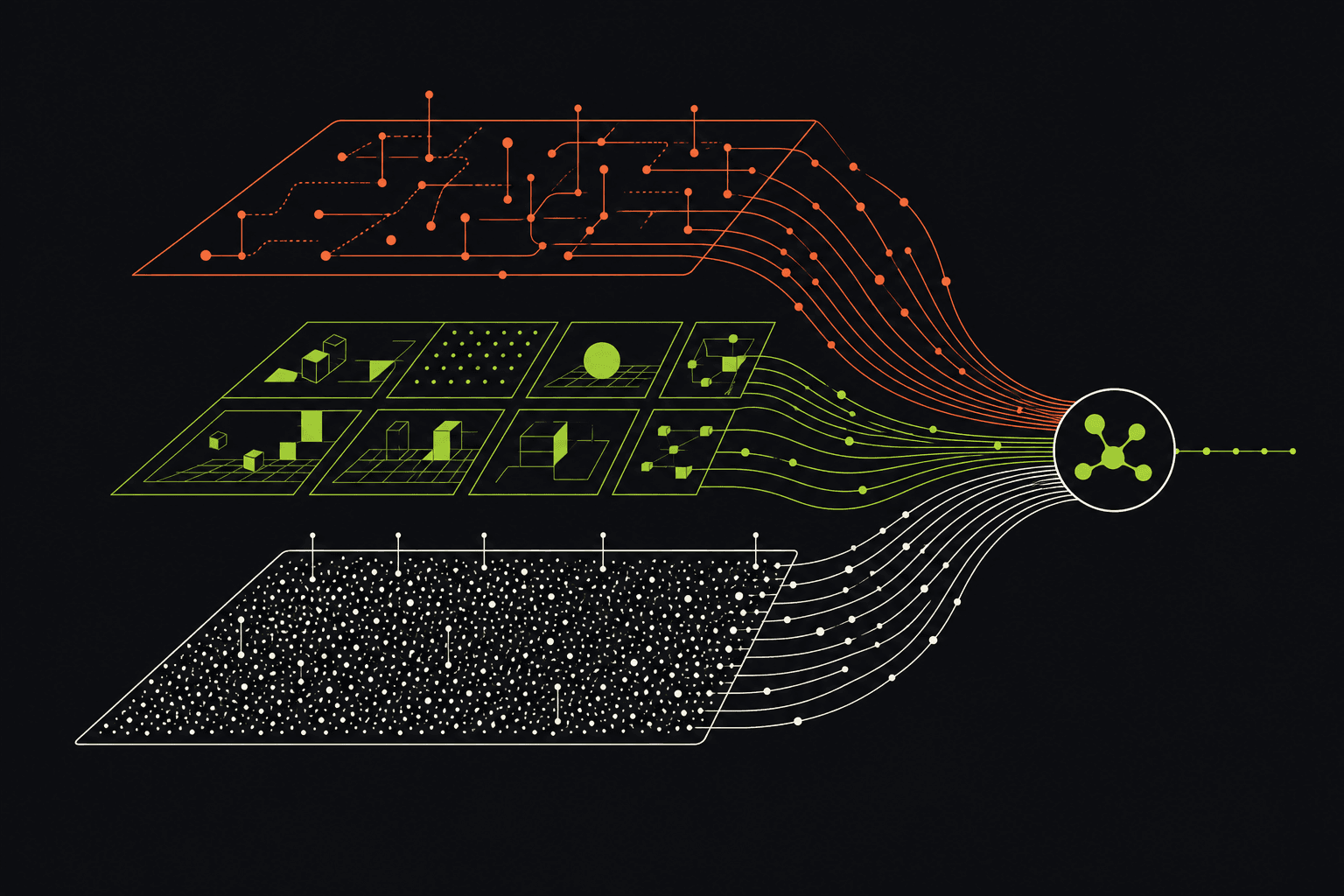
The way out is not one dataset. It is a layered data system. At the base is internet-scale video and image data. It is not captured from the robot’s perspective, but it contains a huge amount of implicit knowledge about how the physical world behaves: objects fall, doors open, hands manipulate tools, kitchens vary, roads change, people move around constraints.
On top of that, world models can learn to understand and simulate physical dynamics. Once a model can simulate plausible futures, it can help generate synthetic data that is more tailored to robot perspective, robot tasks, and robot embodiment.
But synthetic data and internet data are not enough. Robots also need in-robot data: the correspondence between what the robot observes and the actions it takes. Physical intelligence is not just seeing the world. It is learning which action changes the world in the direction of the task.
The Matrix for robots
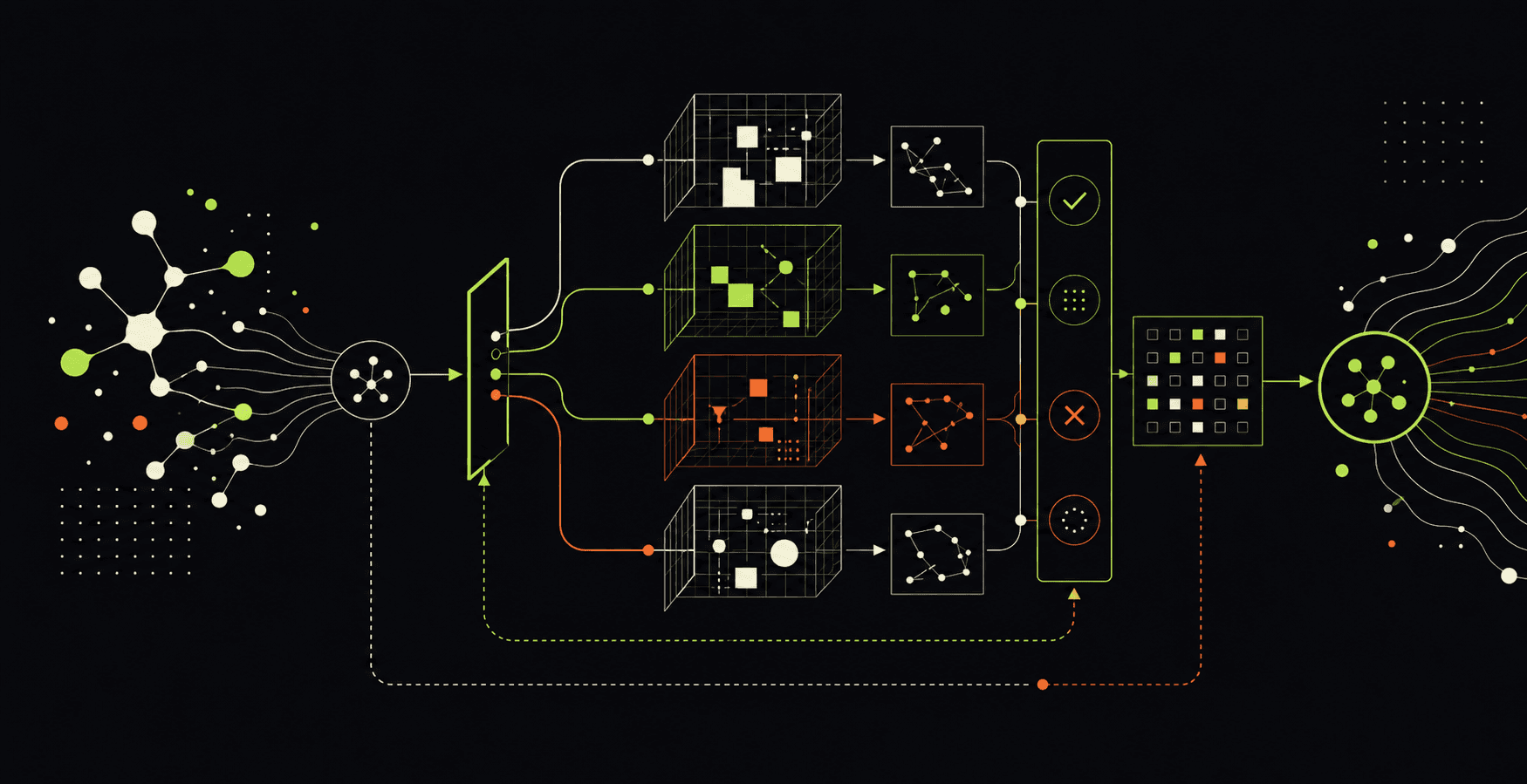
The useful metaphor is not a chatbot. It is a training facility. A physical agent enters an environment with a task, interacts with a simulated world, tries actions, observes new states, receives reward or evaluation, and comes out with a stronger policy.
If the task is to pick up a knife and cut a cucumber in a kitchen, one kitchen is not enough. The system needs many kitchens, many object placements, many lighting conditions, many tool variations, many failure modes, and many ways for the task to almost work but not quite. This is where augmentation becomes strategic. Scale the environments, scale the tasks, and the agent has a better chance of learning a skill that transfers beyond the narrow training scene.
For physical AI, the ambition is a generative training facility: input an agent, environment, and task; output a better agent with a skill that can survive contact with reality.
A world model has to understand and predict
A training facility for robots needs two capabilities. First, understanding: the system has to judge what happened. Did the agent complete the task? Did it violate a constraint? Did it reach the final state in a way that would be safe, reliable, and useful?
Second, prediction: the system has to simulate the future. Given the current state, the task, and an action, what happens next? If the model can roll forward possible futures, then a policy can search through candidate actions before committing them to the physical world.
This is why world models matter. They are not just video generators. They can become evaluation surfaces, planning surfaces, synthetic data engines, and starting points for policy models.
Why synthetic worlds are already useful
The full robot Matrix is not here yet. But the intermediate pieces are already valuable. A physical understanding model can analyze video, sensor streams, factory footage, driving scenes, surgical clips, or robot rollouts and explain what happened. A prediction model can generate likely futures. A transfer model can convert structured simulation outputs into more realistic visual variation.
Those capabilities support practical workflows today. Teams can search and summarize large camera streams. They can create training data for rare or expensive scenarios. They can evaluate policies in a virtual loop before putting every checkpoint on a real machine. They can use predicted futures to expose a policy’s intent.
The strongest idea is compute-for-data: when real-world physical data is scarce, expensive, dangerous, or slow to collect, use world models and simulation to generate more of the right training situations.
Policy evaluation becomes less physical
One of the hardest questions in robotics is simple: which policy checkpoint is best? If a team trains one hundred variants, deploying all of them on real robots is slow, expensive, and sometimes unsafe.
An action-conditioned world model creates a proxy. Connect the policy to the model. Let the policy choose actions. Let the world model predict the resulting states. Then evaluate whether the final state completes the task. If the virtual ranking correlates with real-world performance, development becomes much faster.
This does not remove real-world testing. It changes when and how much of it is needed. The physical world remains the final judge, but simulation can become the filter that decides what deserves to reach that judge.
Model-based planning returns
World models also make planning feel newly relevant. A policy can generate several candidate action chunks. The world model can predict the future states that follow from those candidates. A value function can score which future appears more likely to complete the task. The robot then deploys the best action and repeats the search.
This can matter most in subtle manipulation tasks: grasping objects, opening flexible packaging, folding cloth, placing multiple items, or maintaining contact through a long-horizon sequence. The differences between futures may not be obvious to a human observer, but small differences compound across an episode.
A learned value function gives the system a data-driven way to choose between those futures. That is a practical bridge between reactive policies and deliberative physical agents.
What this means for Mutant Company
For us, the important lesson is that physical AI is not only a robotics problem. It is an infrastructure problem. The winners will build systems that connect world knowledge, synthetic data, in-robot traces, evaluation, planning, and deployment feedback.
In industrial settings, that might mean using world models to train inspection, safety, maintenance, or manipulation systems before exposing them to expensive equipment. In media environments, the same understanding and generation stack can make sense of large video archives, camera systems, production workflows, and embodied capture tools. In enterprise labs, world models give teams a way to test operational ideas before they become procurement programs.
Physical AI will not arrive because one robot suddenly knows everything. It will arrive when organizations build the data flywheel that lets physical agents practice, fail, evaluate, and improve before the real world has to absorb every mistake.